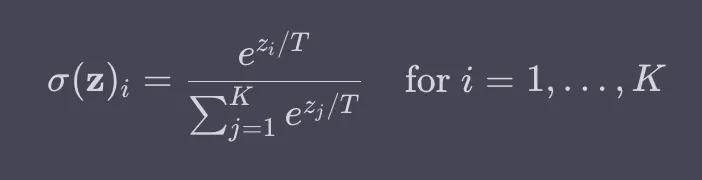The terms "temperature" and "top_p," also known as "nucleus sampling," are hyperparameters used in the context of text generation with large language models like OpenAI's GPT series. They help control the randomness of the text generation process. While they both influence the diversity of the generated text, they operate differently.
Temperature:
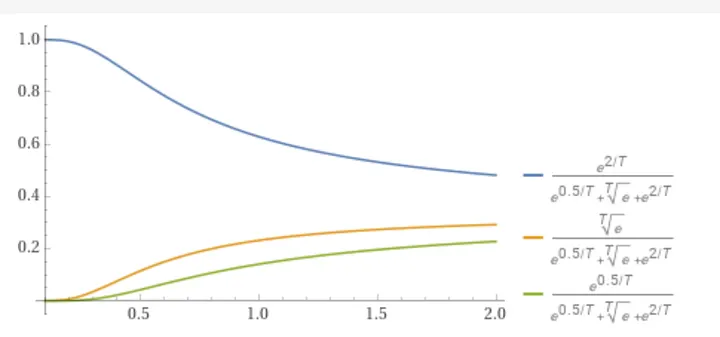
Temperature is a hyperparameter that scales the logits (the inputs to the softmax function that determines the probability distribution over the next token to be generated) before applying softmax. A lower temperature (less than 1) makes the model more confident in its choices, leading to less random outputs that can sometimes be repetitive or predictable. A temperature closer to 0 will make the model always choose the most likely next word, essentially removing randomness. A higher temperature increases randomness, encouraging the model to choose less likely words, which can introduce more variety and creativity but can sometimes result in less coherent text. A temperature of 1 means no scaling is applied, keeping the original logits.
Top_p (Nucleus Sampling):
Top-p, also known as nucleus sampling, is a sampling strategy that involves selecting from the most probable tokens whose cumulative probability mass exceeds a certain threshold (p). Instead of sampling from the entire probability distribution, top-p sampling dynamically truncates the distribution based on the cumulative probabilities until it reaches the threshold p. This allows for controlling the diversity of generated text while ensuring that only a subset of the most probable tokens are considered for sampling.
Both temperature and top_p are used to strike a balance between randomness and determinism during text generation, with temperature generally controlling the "spread" of probabilities over all words, while top_p controls the "cut-off" point beyond which words are no longer considered for sampling. They can be fine-tuned depending on whether you want more creative, diverse, and potentially surprising outputs (high temperature, high top_p) or more predictable, safe, and coherent outputs (low temperature, low top_p).