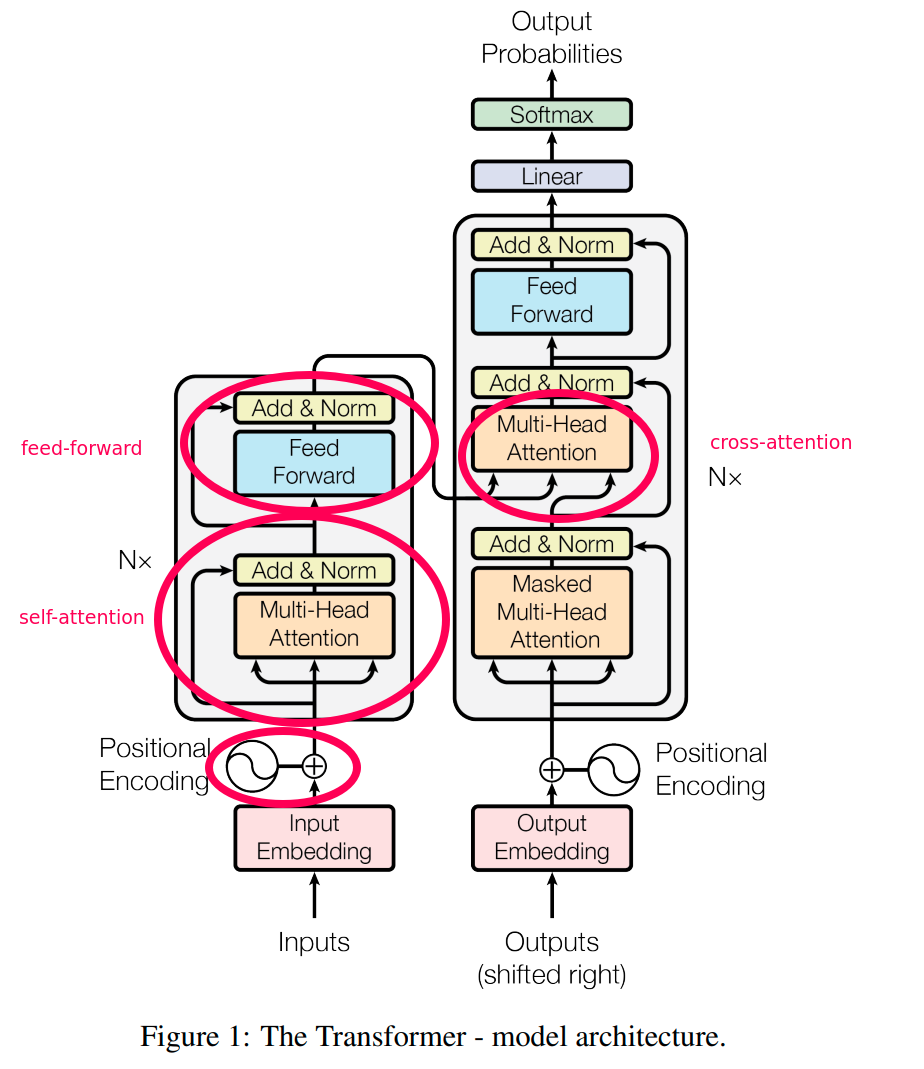
In the context of the Transformer architecture, "attention" generally refers to the ability of the model to focus on different parts of the input sequence when producing an output. "Self-attention," specifically, is a type of attention mechanism that the Transformer model uses to weigh the importance of different positions within the same sequence when encoding or decoding information. Let's break down the differences more clearly:
Attention:
- The term "attention" in neural networks originates from the idea that the model should be able to pay more attention to certain inputs while ignoring others when it's making predictions or generating output.
- In earlier sequence-to-sequence models, attention mechanisms were used to allow the decoder to look back at the input sequence at each step in the output sequence — this is often referred to as "encoder-decoder attention" or "global attention."
- This kind of attention helped deal with the limitations of Encoder-Decoder architectures (like RNNs and LSTMs) by directly modeling the dependencies between the input and output at each step, without having to encode all information into a fixed-length context vector as traditional RNNs did.
Self-Attention:
- Self-attention, also known as "intra-attention," is an attention mechanism that relates different positions of the same input sequence in order to compute a representation of the sequence.
- In the Transformer architecture, self-attention is used in both the encoder and the decoder blocks. In the encoder, self-attention allows the model to consider all parts of the input sequence when encoding each word. In the decoder, self-attention provides a way for each output element to consider other output elements that have been generated so far (in the case of causal or masked self-attention) when predicting the next element.
- The key idea behind self-attention in Transformers is that it computes attention scores for all pairs of positions within the sequence and thus can capture long-range dependencies regardless of their distance in the sequence.
One of the reasons the Transformer architecture is powerful is because it applies self-attention multiple times at different layers and in multiple parallel streams, or "heads" (multi-head self-attention). This allows the model to jointly attend to information from different representation subspaces at different positions, providing a rich and nuanced understanding of the sequence.
In summary, self-attention is a specific form of the broader attention concept, designed to enable a sequence to attend to itself, thereby capturing the internal structure and relationships within the sequence. When discussing the Transformer model, self-attention usually implies this particular intra-sequence attention mechanism that is a core component of the architecture.